
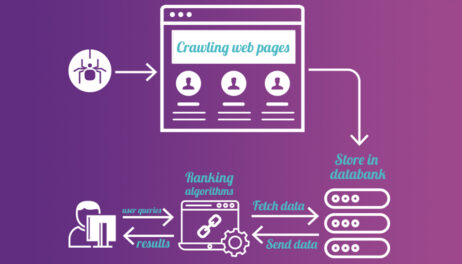
How Search Engine Crawlers Work?
A Web crawler starts with a list of URLs to visit, called the seeds. As the crawler visits these URLs, it identifies all the hyperlinks in the page and adds them to the list of URLs to visit, called the crawl frontier. URLs from the frontier are recursively visited according to a set of policies.… Continue reading How Search Engine Crawlers Work?
Read More
